History
In July 2014, the Termcoord of the Translation Centre for the Bodies of the European Union published a large data base (2.2 GB) on its webpage (Download IATE Termbase) – with the intention to make their information accessible for users for their own purposes. The data base now contains 1.3 million multilingual entries. Of course, most of the (prospective) users are translators, not linguists or terminologists, just because there are many more from the first category. However, when a translator wants to extract data from the data base in order to integrate them in his own CAT-tools, he is met with a large number of problems.
Change history
– Version 2015 of IATE data base; added possibility of extracting subsets
– Version 2016 – over 22,000 terms added, modified or deleted; new IATE domain structure implemented; Domain names now output in target language
– Version 2017 – even more changes implemented by IATE, around 80,000 changes (deletions and additions)
– Version 2018 – The pruning and renewing process in IATE continues. Where the total number of terms has decreased by about 13,000 since March 2017, additions and deletions of complete term entries are as follows:
23,645 termentries deleted, 79,826 term entries added.
– Version 2019 – Apart from numerous new entries and deletions by IATE linguists, latin and multilingual terms, introduced earlier in IATE, are now added to both source- and target terms of the relevant entries. This is especially important for those working in botany, chemistry, law, trade, food…
In Jan 2015, the Termcoord has published an updated version of its data base; apart from adding new terms (and delete some) they also removed some of the most obvious flaws of their data base, viz. html tags and/or formatting strings, but most other problems as listed below have not been touched.
These problems are detailed further below on this page; if you want to skip the details now, go to What you get…
Obviously, as the size of that database is so large, handling it is a daunting task.
Various attempts to attack this problem of size have been published, for instance, with the latest version of Xbench3.0 (build 1243) you can extract language pairs and create output in diverse formats.
Also, a method was described by Paul Filkin from SDL on his blog Multifarious (What a Whopper!) to extract more languages together and construct an SDL Termbase.
Recently, the IATE Termcoord has published a tool enabling the user to extract one or more subsets, ordered along languages and Domains; this alleviates the problem of handling the large dbx file but leaves all other problems untouched. Also, you can select to extract only one (sub)domain at a time, and an important Domain group cannot even be extracted at all!
Using either one of these (complicated and time-consuming) methods in order to arrive at a term base for pure translation work, the results are less than convincing, because of the reasons explained below.
Description of the problem areas
Although the methods mentioned above may result in smaller databases that eventually could be used as input for a bi-, tri- or multilingual term base or translation memory, these still are not well suited for use in a pure translation environment. The reasons therefore are numerous.
- handling of synonyms – sometimes synonyms are strung together within one text record, separated by a semicolon or a pipe symbol (|), sometimes they get separate text records;
- context notes are sometimes inserted in the text record between square brackets;
- the term base lists subjects as numerical codes, that can only be resolved after consulting the code definitions on the IATE website
- the term base contains text entries varying from just one word or expression up to complete sentences, inclusive remarks and explanations; these longer text entries have no purpose in a term base.
- the IATE file contains numerous non-UTF-8 characters
- many of the first users complained about the occurrence of a lot of 1-, 2- and even 3-letter words; others did not want ACRONYMS and abbreviations in their term base, or at least have the possibility to create separate term bases for these terms.
- Since many entries in the IATE file have multiple (sub)domains assigned, merging separately extracted files from multiple domains into one data base can lead to a substantial overlap caused by duplicate entries.
In the following examples, you will see some of the problems illustrated.
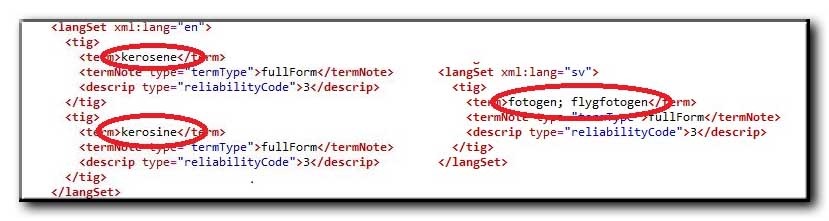
1 – Synonyms
The following picture shows two forms of synonyms in the IATE database: in the Portuguese term set two terms are defined, in the Swedish term set the synonyms are separated by a semicolon within one term definition. No standard extraction- or CAT program can cope with these two methods of synonym definition at the same time. For instance, when Xbench extracts the language pairs, the first English synonym is completely missed. When the database is converted into an SDL Studio TermBase, the second form is not recognized as containing synonyms.
2 – Context
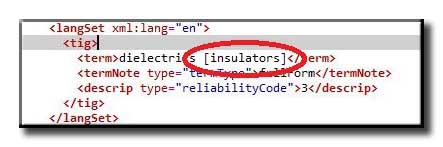
Very often, context is added to a term description; although the information is useful when you look up a term, it is very disturbing if you just need a match of the word dielectrics.
3 – Subject
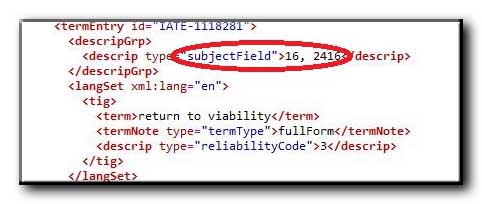
For almost all term entries, a Subject is defined. This definition might help decide whether the term is applicable in the context of the translation. However, this definition is in the form of a numerical code, the meaning of which is only to be found on the IATE website. This is very impractical, to say the least. In this case, the meaning of the codes is “ECONOMICS”, “Financial institutions and credit”.
4 – Long text entries
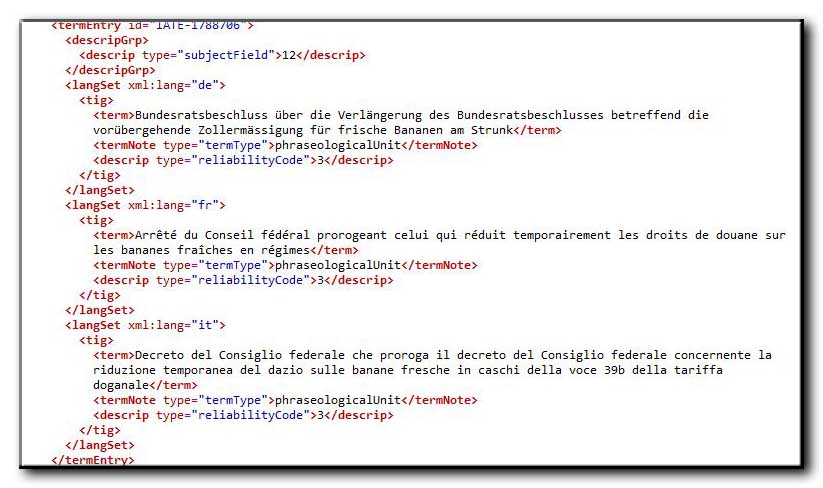
You would not like to have sentences as long as this one in your Term Base – they should go into a Translation Memory
If you are interested in the solution of these problems, go to the next page